Improving Structured Outputs from LLMs: A Two-Step Pattern
Large language models can reason about complex input. They can also follow formatting instructions. But when asked to do both at once, they often fail. For example, turning messy data into valid structured output usually leads to errors or oversimplification. This post explains a two-step method that improves reliability by separating the thinking from the formatting.
The Challenge: One-Shot Structuring Falls Short
The goal is straightforward: transform messy, unstructured inputs, like discussions from Reddit threads, into clean, structured outputs. For instance, imagine turning a bunch of user comments into a marketing research document with a fixed schema, including fields like title, summary, and insights.
At first glance, this seems simple. Just prompt the model once:
"Read these posts, extract the key insights, and output them as JSON following this schema."
But in practice, this one-shot approach often leads to issues:
- Missing nuance: The model might overlook subtle contradictions or trends in the data.
- Repetition: It could repeat the same points unnecessarily.
- Oversimplification: Interesting details get flattened into generic statements.
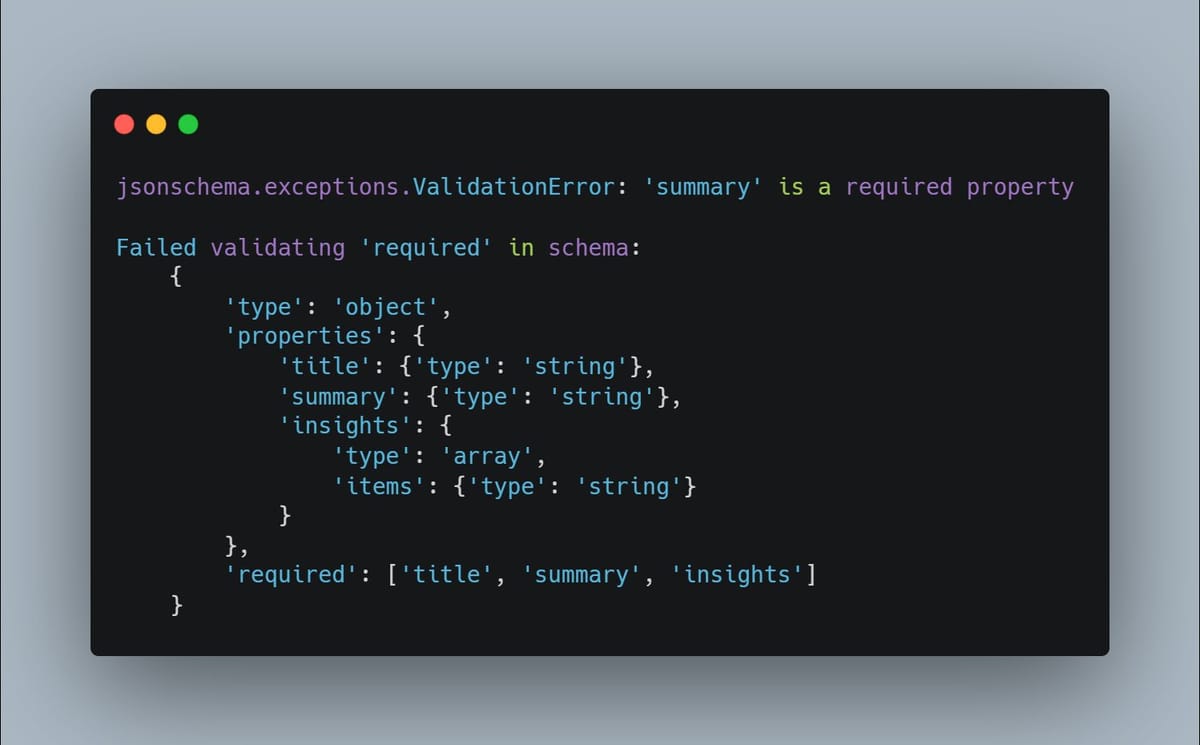
- Schema errors: Occasionally, the output doesn't even validate against your schema, like forgetting required fields such as "summary."
The Elder Scripts blog covers the opportunities and challenges that software engineers and data engineers encounter. I am sharing insights gained from years of work in the industry as an engineer and as a manager of engineering teams. Subscribe to get notified of new posts if you haven't already.
Here's an example of what that schema failure might look like in code:
jsonschema.exceptions.ValidationError: 'summary' is a required property
Failed validating 'required' in schema:
{
'type': 'object',
'properties': {
'title': {'type': 'string'},
'summary': {'type': 'string'},
'insights': {
'type': 'array',
'items': {'type': 'string'}
}
},
'required': ['title', 'summary', 'insights']
}
This kind of error highlights how LLMs can struggle when juggling comprehension and strict formatting in a single pass.
The Solution: Split into Thinking and Structuring Steps
What works better is dividing the task into two phases. This allows each step to play to the strengths of different models and prompting styles.
Step 1: Free-Form Summarization (The "Thinking" Step)
In the first pass, focus solely on comprehension and insight extraction. Use a more capable model (like a higher-end one) with a higher temperature setting to encourage creativity. Don't worry about structure yet. Ask the model to read the input and produce a free-form list of findings, trends, contradictions, and anything else noteworthy.
For example, here's a sample prompt for this step in a market research context:
You are a senior market research analyst conducting a comprehensive market analysis.
PROJECT: {project_terms}
DESCRIPTION: {project_description}
QUANTITATIVE DEMAND METRICS:
- Total posts found: {demand_metrics[total_posts]}
- Median engagement score: {demand_metrics[median_score]}
- High engagement posts (score >=10): {demand_metrics[high_engagement_posts]}
- Raw interest posts: {raw_interest_posts}
- Recommendation request posts: {demand_metrics[recommendation_posts]}
- Competitive landscape posts: {demand_metrics[competitive_landscape_posts]}
REDDIT DISCUSSIONS ANALYZED ({content_count} high-quality posts/comments):
{combined_content}
Based on this data, write a comprehensive market research report that covers [...]This thinking step generates a rich, unstructured summary that is closer to human-like analysis.
Step 2: Strict Formatting (The "Structuring" Step)
Now take that free-form output and feed it into a second pass. Use a cheaper, more precise model (for example, GPT-3.5) with a stricter prompt and lower temperature to reduce variability. The instruction here is simple: Reformat the provided summary into your exact schema. No new insights, just faithful structuring.
A sample prompt for this step might look like:
You are a data analyst tasked with converting a market research report into structured JSON format.
ORIGINAL ANALYSIS:
{freeform_analysis}
DEMAND METRICS TO INCLUDE:
{json_dumps(demand_metrics, indent=2)}
Convert this analysis into the following exact JSON structureBy separating the steps, the second model acts like a diligent formatter. It turns the insightful summary into a clean, schema-compliant document.
Why This Pattern Works: Key Benefits
This two-step approach is not complicated, but it is effective. Here's why:
- Tunable models: Use a creative model for insight extraction and a precise one for formatting.
- Fewer hallucinations: Each step carries less complexity, which reduces schema errors.
- Richer content: The free-form pass captures more detail without the constraints of structure.
- Cost efficiency: The second step runs on a cheaper model.
- Easier debugging: You can isolate problems to either the thinking or the structuring phase.
This is especially helpful when accuracy and structure both matter. LLMs are good at analysis. They are also good at formatting. They are not good at doing both in one step.
Final Thoughts
To summarise:
- Extract insights in a free-form way with a capable model.
- Structure those insights strictly with a precise model and schema.
This simple change outperforms more elaborate one-shot prompt engineering in most cases. If your structured outputs are failing because of hallucinations, oversimplification, or schema mismatches, try this method. It may save you a lot of frustration.
What do you think?
Have you encountered similar issues with structured LLM outputs? Please let me know on Twitter or at theelderscripts@gmail.com.