Baking the context cake

If you ask 10 executives which roles they need to run an AI adoption project in their company, 9 of them won't mention data engineers. The AI development community spent immense effort in the past few years working on models and orchestration methods, but only recently we started to pay real attention to context that AI operates with. I believe this is a major reason why 80% of enterprise AI projects fail, and leading agents complete only 30-35% of multi-step tasks.
Let's review together the recent advances in the area of context management, and see why context is much more than just search over company documents.
A deceptively simple problem
As LLMs grew in their capabilities, developers started using two major ways of grounding them in relevant knowledge: adding whole documents as part of the prompt, and giving the model access to tools such as search or retrieval APIs.
It is easy to see why the former approach doesn't scale well. Even if the frontier models support context length of 1 million tokens, in practice their ability to refer to knowledge passed in the prompt diminishes quickly. This problem came to be known as "context rot".
Tool-based approach offers higher scalability on the surface. Indeed, it shouldn't matter how many documents you push into an Elasticsearch cluster, if the model can just search over them and pull the information it needs. Once you dig deeper though, you notice that even recent models tend to get confused with the number of tools available to them. That's in addition to all the usual concerns that go into organizing a well structured search engine: indexing and retrieval performance, access control, ranking etc.
On top of this, think about what we want the agents to know to do their tasks well. It's not just company documentation or emails, they also need to access aggregated data such as financial reports or product metrics. We could allow an agent to send SQL queries to the data warehouse, but how would the poor thing make sense of those 10 years of accumulated migrations and schema changes?
The problem of context management requires a solution that:
- scales well with the size of the organization's knowledge base,
- allows both fact retrieval and aggregation queries,
- and with all that, is tailored to a form that agents can successfully use.
Thinking in layers
Back in January OpenAI released an article titled "Inside OpenAI’s in-house data agent". The article explained how they built the agent that answers "high-impact data questions" through natural language. In other words, teams like Finance, Engineering or GTM use this agent to evaluate new product launches or track financial health.
On the scale that OpenAI operates, they couldn't just give the agent access to their datalake or warehouse and leave it to run SQL queries. Even for users that are familiar with the structure of the internal database and the schema of major tables, producing these reports is a daunting task. Invite your fellow data analyst for a beer, and you will surely and quickly understand how complicated this can get. You need to know where the data is coming from (what's called data lineage), how frequently it is updated, whether it is accurate and who is responsible for producing it. You also need to be able to link warehouse tables to company's vocabulary: which table contains "customers", which contains "orders" and how they are related.
All these concerns led OpenAI to a layered approach to context retrieval.
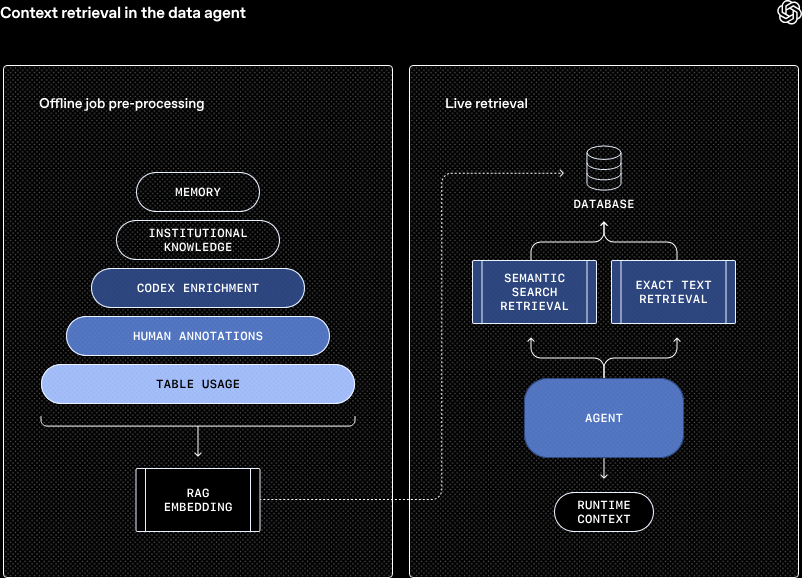
In order to understand the company's data and the user's request, the agent reads from the following sources:
- Historical view on table usage. The agent recognizes which tables are frequently joined together.
- Human annotations. Curated descriptions provided by experts.
- Codex enrichment. Codebase provides insights into how data is produced and transformed.
- Institutional knowledge. Documentation from Slack, Google Docs or Notion.
- Memory. When the agent is given corrections or discovers nuances about certain data questions, it's able to save these learnings for next time.
- Runtime context. The agent issues live queries to the warehouse in order to infer additional details about data and schema.
As a data engineer myself, I can't help but be amused at how much complex processing goes into approximating what my fellow DEs do daily.
OpenAI proposes the terminology of context layers that allow the agent to retrieve the necessary information from various sources at different granularity. We will see that OpenAI's agent is not unique in this, and in fact we can speak of an emerging pattern for context management.
Layered Context Pattern
In the recent months several other companies shared their approach to building organizational context: Writer, Glean, Sentra, Embra, Zep. We have also seen open source projects in this area: Mem0, Databao, Graphiti.
In these projects we can see a common pattern, although implemented in very different ways: layered context indexing and retrieval.
This pattern aims to support various types of queries: granular fact retrieval, summaries of larger topics, aggregated metrics. In order to achieve this, knowledge is collected and organized in different systems:
- Search over documentation, on the level of whole documents or chunks. This search often relies on a combination of lexical and semantic approaches.
- Entity layer which captures structured relationships between entities described in the documents. Graph databases provide a good storage and retrieval basis for this data.
- Catalog/topic layer. Engineers use LLMs to extract summaries from documents and group them into topics. This gives agents the ability to understand larger corpuses of text and route their requests to the right clusters of topics.
- Runtime/live layer. Agents have the capability to access databases and warehouses to retrieve information or run aggregation queries.
Some projects extend this basic pattern with more sophisticated approaches to creating and managing memory. For example, Zep/Graphiti employ a bi-temporal model: they track when facts occurred and when they were recorded. This helps agents distinguish outdated information from current truth.
Future of context
Most of the tools used in context management are not new. Lexical and semantic search or graph databases have been an area of active development for years and decades. We are now "just" composing them in a way that is accessible for modern LLMs and agents. This composition in itself brings new questions and problems. For instance, conflict resolution is a hot topic that is still unsolved at scale. When multiple sources say different things, someone has to decide what to do with them: merge, invalidate or skip entirely. Mem0 uses LLM-powered resolution, but at scale it is expensive and non-deterministic.
Resolving access and governance issues across different sources is another problem that will have to be solved at enterprise scale. Security of data and organization content is paramount and will have to be carefully balanced against usability and reliability of agentic systems.
Given that AI adoption in enterprise is only just beginning to rely on agents, I see strong indication that context engineering will be a major factor in adoption projects going on. Projects like OpenAI's Frontier and Jetbrains' Databao show that it is also a major target of investment these days.
Sources and further reading


